|
I am a Research Scientist at Adobe Research. Previously, I was a researcher at Sony AI after a postdoctoral fellowship at Microsoft Research, prior to which I graduated with a PhD in Computer Science from The University of Texas at Austin and MS in Robotics from Carnegie Mellon University. I was the President's Gold Medalist for my undergraduate studies in Computer Science and Engineering at IIT Jodhpur. Broadly, I am very interested in research problems related to human-interactive machine learning and sequential decision making, applied to both digital and embodied AI agents. My scientific curiosity is often driven by research questions derived from real-world applications. Several of my projects have been tested/deployed on end-user products and applications. Email / Google Scholar / GitHub / LinkedIn / Bluesky |

|
|
|
α-β indicates alphabetical author order, * indicates equal contribution |
 |
pdf |
abstract |
bibtex
Reinforcement learning has proven to be a valuable tool in the creation of advanced AI and robotic systems, contributing to everything from game playing to robotics to foundation models. Through trial-and-error, these AI systems typically learn one, near-optimal behavior to solve their tasks. However, there are many use cases in which one would like to assert some level of control, preferably in real time, over how the task is solved. We refer to these modifications of a core task as styles. We combine universal value function approximators (UVFAs) with carefully selected training scenarios, learning algorithms, and data augmentation to create a framework for coaching agents that exhibit styles in complex domains. We demonstrate the framework's application in the AAA video games Horizon Forbidden West and Gran Turismo, and in an open-source humanoid test domain. Despite the different nature of the domains -- car racing, stylized game combat, and humanoid walking -- each agent shows strong coherence to the style requests while still satisfying the main task in its domain. Importantly, the techniques outlined in this paper allow an end user to choose the final behavior at run time, giving them flexible control over the final executed performance.
@article{capobianco2026coachable,
title={Coachable Agents for Interactive Gameplay},
author={Capobianco, Roberto and van Seijen, Harm and Bard, Nolan D. and Burch, Neil
and Davelouis, Fatima and Davidson, Josh and Devlic, Alisa and Du, Yunshu
and Durugkar, Ishan and Saran, Akanksha and others},
journal={arXiv},
year={2026}
}
A framework for coaching RL agents to exhibit user-selectable "styles" at run time while still solving the core task, demonstrated across game combat, car racing, and humanoid walking. |
 |
pdf |
abstract |
bibtex |
project webpage
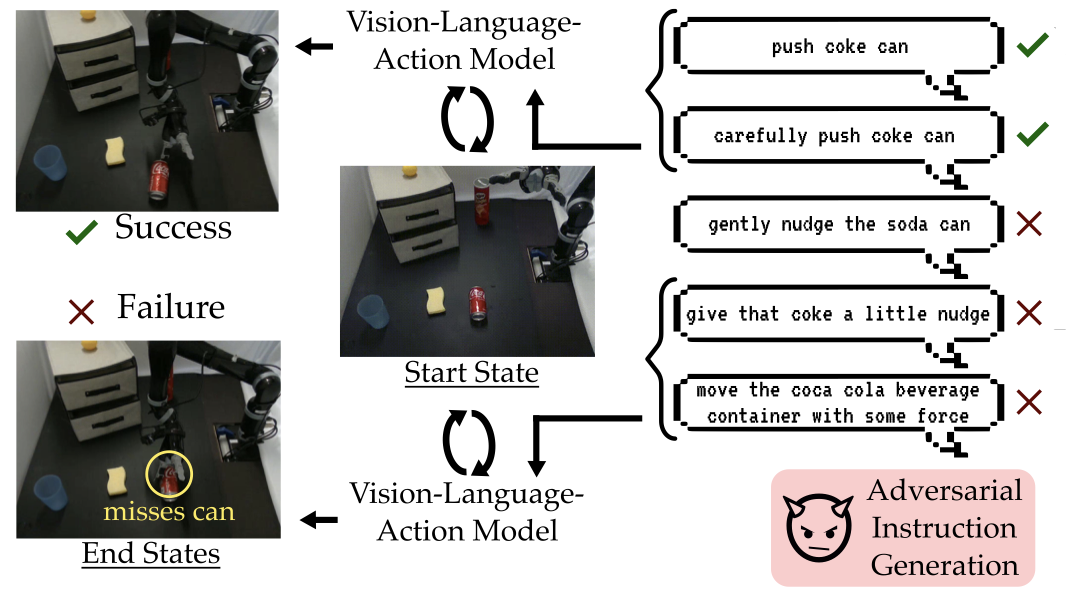
Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots.
@article{srikanth2026red,
title={Red-Teaming Vision-Language-Action Models via Quality Diversity
Prompt Generation for Robust Robot Policies},
author={Srikanth, Siddharth and Liang, Freddie and Hsu, Sophie and Bhatt, Varun
and Zhao, Shihan and Chen, Henry and Tjanaka, Bryon and Hwang, Minjune
and Saran, Akanksha and Seita, Daniel and Tabrez, Aaquib and Nikolaidis, Stefanos},
journal={arXiv},
year={2026}
}
A method that leverages Quality Diversity and VLMs to automatically generate diverse, adversarial natural language instructions, which are then used to expose vulnerabilities and improve the robustness of VLAs through fine-tuning. |
 |
pdf |
abstract |
bibtex
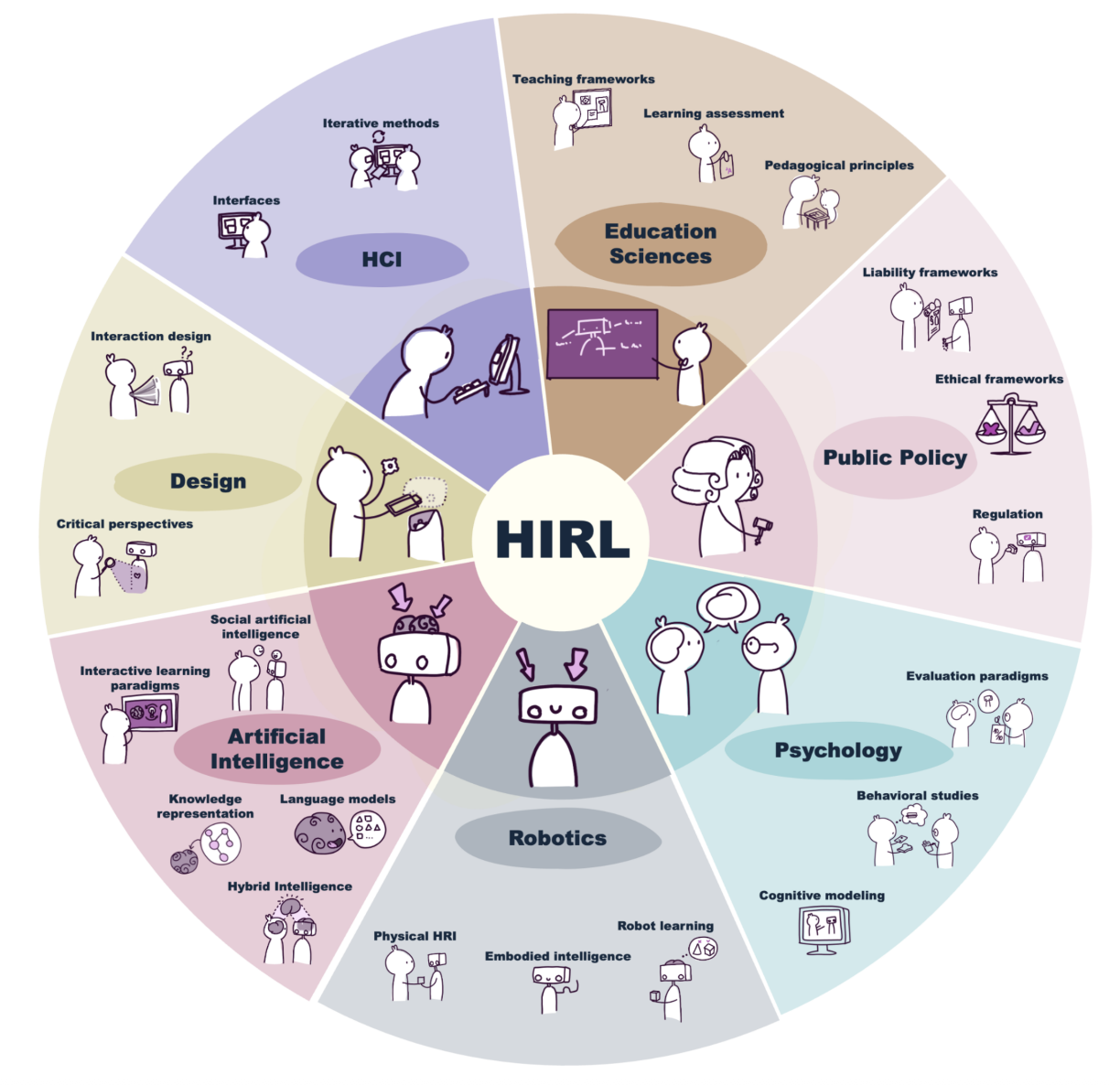
Robot learning from humans has been proposed and researched for several decades as a means to enable robots to learn new skills or adapt existing ones to new situations. Recent advances in artificial intelligence, including learning approaches like reinforcement learning and architectures like transformers and foundation models, combined with access to massive datasets, has created attractive opportunities to apply those data-hungry techniques to this problem. We argue that the focus on massive amounts of pre-collected data, and the resulting learning paradigm, where humans demonstrate and robots learn in isolation, is overshadowing a specialized area of work we term Human-Interactive-Robot-Learning (HIRL). This paradigm, wherein robots and humans interact during the learning process, is at the intersection of multiple fields (artificial intelligence, robotics, human-computer interaction, design and others) and holds unique promise. Using HIRL, robots can achieve greater sample efficiency (as humans can provide task knowledge through interaction), align with human preferences (as humans can guide the robot behavior towards their expectations), and explore more meaningfully and safely (as humans can utilize domain knowledge to guide learning and prevent catastrophic failures). This can result in robotic systems that can more quickly and easily adapt to new tasks in human environments. The objective of this paper is to provide a broad and consistent overview of HIRL research and to guide researchers toward understanding the scope of HIRL, and current open or underexplored challenges related to four themes --- namely, human, robot learning, interaction, and broader context. The paper includes concrete use cases to illustrate the interaction between these challenges and inspire further research according to broad recommendations and a call for action for the growing HIRL community.
@article{baraka2025human,
title={Human-Interactive Robot Learning: Definition, Challenges,
and Recommendations},
author={Baraka, Kim and Faulkner, Taylor Kessler and Biyik, Erdem and Booth, Serena
and Chetouani, Mohamed and Grollman, Daniel H and Saran, Akanksha and Senft, Emmanuel
and Tulli, Silvia and Vollmer, Anna-Lisa and others},
journal={ACM Transaction on Human-Robot Interaction (THRI)},
year={2025}
}
A roadmap for the Human-Interactive Robot Learning (HIRL) community to prioritize richer human-robot dialogue, safety-aware exploration, and shared interdisciplinary benchmarks to drive the next wave of sample-efficient, human-aligned robot learning. |
 |
pdf |
abstract |
bibtex
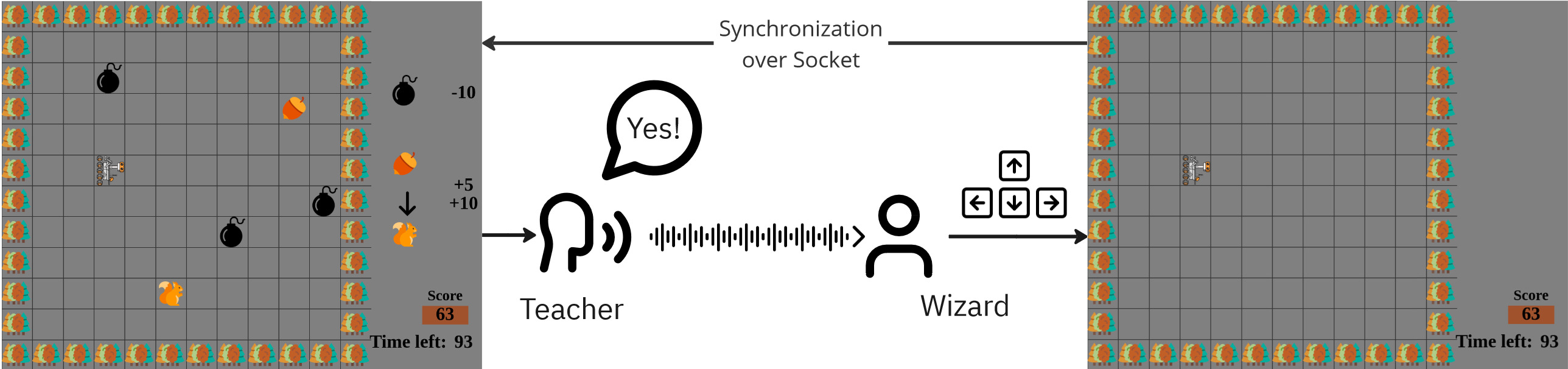
Gaze tracking devices have the potential to expand interactivity greatly, yet miscalibration remains a significant barrier to use. As devices miscalibrate, people tend to compensate by intentionally offsetting their gaze, which makes detecting miscalibration from eye signals difficult. To help address this problem, we propose a novel approach to seamless calibration based on the insight that the system's model of eye gaze can be updated during reading (user does not compensate) to improve calibration for typing (user might compensate). To explore this approach, we built an auto- calibrating gaze typing prototype called EyeO and ran a user study with 20 participants. Our user study results suggest that seamless autocalibration can significantly improve typing efficiency and user experience.
@article{saran2023eyeo,
title={EyeO: Autocalibrating Gaze Output with Gaze Input},
author={Saran, Akanksha and Alber, Jacob and Zhang, Cyril
and Paradiso, Ann and Bragg, Danielle and Langford, John},
journal={arXiv preprint arXiv:2307.15039},
year={2023}
}
Leveraging eye gaze fixations during reading can be useful to implicitly autocalibrate eye trackers for improved gaze typing. |
 |
pdf |
abstract |
bibtex |
code
Agent learning from human interaction often relies on explicit signals, but implicit social cues, such as prosody in speech, could provide valuable information for more effective learning. This paper advocates for the integration of prosody as a teaching signal to enhance agent learning from human teachers. Through two exploratory studies --- one examining voice feedback in an interactive reinforcement learning setup and the other analyzing restricted audio from human demonstrations in three Atari games --- we demonstrate that prosody carries significant information about task dynamics. Our findings suggest that prosodic features, when coupled with explicit feedback, can enhance reinforcement learning outcomes. Moreover, we propose guidelines for prosody-sensitive algorithm design and discuss insights into teaching behavior. Our work underscores the potential of leveraging prosody as an implicit signal for more efficient agent learning, thus advancing human-agent interaction paradigms.
@article{knierim2024prosody,
title={Prosody as a Teaching Signal for Agent Learning:
Exploratory Studies and Algorithmic Implications},
author={Knierim, Matilda and Jain, Sahil and Han Aydoğan, Murat
and Mitra, Kenneth and Kush Desai and Saran, Akanksha and Baraka, Kim},
journal={ACM International Conference on Multimodal Interaction (ICMI)},
year={2024}
}
Prosodic cues from human teachers can enhance learning outcomes for reinforcement learning and imitation learning paradigms. |
 |
pdf |
abstract |
bibtex |
poster |
talk video
We study pre-training representations for decision-making using video data, which is abundantly available for tasks such as game agents and software testing. Even though significant empirical advances have been made on this problem, a theoretical understanding remains absent. We initiate the theoretical investigation into principled approaches for representation learning and focus on learning the latent state representations of the underlying MDP using video data. We study two types of settings: one where there is iid noise in the observation, and a more challenging setting where there is also the presence of exogenous noise, which is non-iid noise that is temporally correlated, such as the motion of people or cars in the background. We study three commonly used approaches: autoencoding, temporal contrastive learning, and forward modeling. We prove upper bounds for temporal contrastive and forward modeling in the presence of only iid noise. We show that these approaches can learn the latent state and use it to do efficient downstream RL with polynomial sample complexity. When exogenous noise is also present, we establish a lower bound result showing that learning from video data can be exponentially worse than learning from action-labeled trajectory data. This partially explains why reinforcement learning with video pre-training is hard. We evaluate these representational learning methods in two visual domains, yielding results that are consistent with our theoretical findings.
@inproceedings{misra2024towards,
title={Towards Principled Representation Learning
from Videos for Reinforcement Learning},
author={Misra, Dipendra and Saran, Akanksha and Xie, Tengyang and Lamb,
Alex and Langford, John.},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}
Theoretical analysis and experiments concerning the value reinforcement learning can gain from pretrained representations of unlabeled video data. |
 |
pdf |
abstract |
bibtex |
code |
poster |
talk video
Active learning is perhaps most naturally posed as an online learning problem. However, prior active learning approaches with deep neural networks assume offline access to the entire dataset ahead of time. This paper proposes VeSSAL, a new algorithm for batch active learning with deep neural networks in streaming settings, which samples groups of points to query for labels at the moment they are encountered. Our approach trades off between uncertainty and diversity of queried samples to match a desired query rate without requiring any hand-tuned hyperparameters. Altogether, we expand the applicability of deep neural networks to realistic active learning scenarios, such as applications relevant to HCI and large, fractured datasets.
@article{saran2023streaming,
title={Streaming Active Learning with Deep Neural Networks},
author={Saran, Akanksha and Yousefi, Safoora and Krishnamurthy, Akshay
and Langford, John and Ash, Jordan T.},
journal={arXiv preprint arXiv:2303.02535},
year={2023}
}
An approximate volume sampling approach for streaming batch active learning. |
.png) |
pdf |
abstract |
bibtex |
code |
poster |
slides |
blog |
blog |
talk video
In an era of countless content offerings, recommender systems alleviate information overload by providing users with personalized content suggestions. Due to the scarcity of explicit user feedback, modern recommender systems typically optimize for the same fixed combination of implicit feedback signals across all users. However, this approach disregards a growing body of work highlighting that (i) implicit signals can be used by users in diverse ways, signaling anything from satisfaction to active dislike, and (ii) different users communicate preferences in different ways. We propose applying the recent Interaction Grounded Learning (IGL) paradigm to address the challenge of learning representations of diverse user communication modalities. Rather than taking a fixed, human-designed reward function, IGL is able to learn personalized reward functions for different users and then optimize directly for the latent user satisfaction. We demonstrate the success of IGL with experiments using simulations as well as with real-world production traces.
@inproceedings{maghakian2023personalized,
title={Personalized Reward Learning with Interaction-Grounded Learning},
author={Maghakian, Jessica and Mineiro, Paul and Panaganti, Kishan
and Rucker, Mark and Saran, Akanksha and Tan, Cheng},
booktitle={International Conference on Learning Representations (ICLR)},
year={2023}
}
A novel personalized variant of IGL: the first IGL strategy for context-dependent feedback, the first use of inverse kinematics as an IGL objective, and the first IGL strategy for more than two latent states. |
|
|
pdf |
abstract |
bibtex |
code |
project webpage |
talk video |
blog
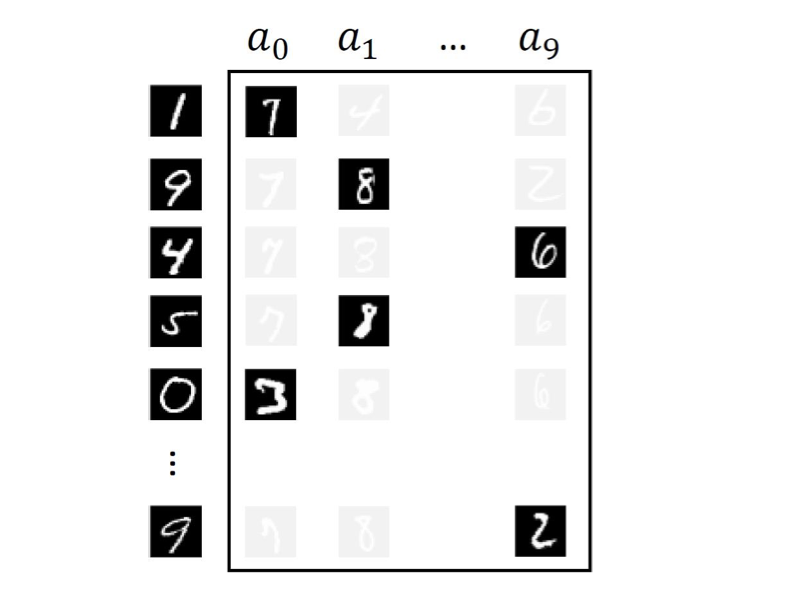
We propose a new framework for imitation learning — treating imitation as a two-player rankingbased Stackelberg game between a policy and a reward function. In this game, the reward agent learns to satisfy pairwise performance rankings within a set of policies, while the policy agent learns to maximize this reward. This game encompasses a large subset of both inverse reinforcement learning (IRL) methods and methods which learn from offline preferences. The Stackelberg game formulation allows us to use optimization methods that take the game structure into account, leading to more sample efficient and stable learning dynamics compared to existing IRL methods. We theoretically analyze the requirements of the loss function used for ranking policy performances to facilitate near-optimal imitation learning at equilibrium. We use insights from this analysis to further increase sample efficiency of the ranking game by using automatically generated rankings or with offline annotated rankings. Our experiments show that the proposed method achieves state-of-the-art sample efficiency and is able to solve previously unsolvable tasks in the Learning from Observation (LfO) setting.
@inproceedings{sikchi2022ranking,
title={A Ranking Game for Imitation Learning},
author={Sikchi, Harshit and Saran, Akanksha and Goo,
Treating imitation learning as a two-player ranking game between a policy and a reward function can solve previously unsolvable tasks in the Learning from Observation (LfO) setting. |
 |
pdf |
abstract |
bibtex |
code |
poster |
talk video
Consider the problem setting of Interaction-Grounded Learning (IGL), in which a learner's goal is to optimally interact with the environment with no explicit reward to ground its policies. The agent observes a context vector, takes an action, and receives a feedback vector, using this information to effectively optimize a policy with respect to a latent reward function. Prior analyzed approaches fail when the feedback vector contains the action, which significantly limits IGL's success in many potential scenarios such as Brain-computer interface (BCI) or Human-computer interface (HCI) applications. We address this by creating an algorithm and analysis which allows IGL to work even when the feedback vector contains the action, encoded in any fashion. We provide theoretical guarantees and large-scale experiments based on supervised datasets to demonstrate the effectiveness of the new approach.
@inproceedings{xie2022interaction,
title={Interaction Grounded Learning with Action-Inclusive Feedback},
author={Xie, Tengyang and Saran, Akanksha and Foster, Dylan and
An algorithm (AI-IGL) that learns to interpret signals from a controller in an interactive loop without any formal calibration of signal to control --- leveraging implicit feedback which can include the action information, but no explicit rewards are available. |
 |
pdf |
abstract |
bibtex |
spotlight
Humans use audio signals in the form of spoken language or verbal reactions effectively when teaching new skills or tasks to other humans. While demonstrations allow humans to teach robots in a natural way, learning from trajectories alone does not leverage other available modalities including audio from human teachers. To effectively utilize audio cues accompanying human demonstrations, first it is important to understand what kind of information is present and conveyed by such cues. This work characterizes audio from human teachers demonstrating multi-step manipulation tasks to a situated Sawyer robot using three feature types: (1) duration of speech used, (2) expressiveness in speech or prosody, and (3) semantic content of speech. We analyze these features along four dimensions and find that teachers convey similar semantic concepts via spoken words for different conditions of (1) demonstration types, (2) audio usage instructions, (3) subtasks, and (4) errors during demonstrations. However, differentiating properties of speech in terms of duration and expressiveness are present along the four dimensions, highlighting that human audio carries rich information, potentially beneficial for technological advancement of robot learning from demonstration methods.
@inproceedings{saran2022understanding,
title={Understanding acoustic patterns of human teachers
Audio cues of human demonstrators carry rich information about subtasks and errors of multi-step manipulation tasks. |
 |
pdf |
abstract |
bibtex |
code |
slides |
spotlight |
blog
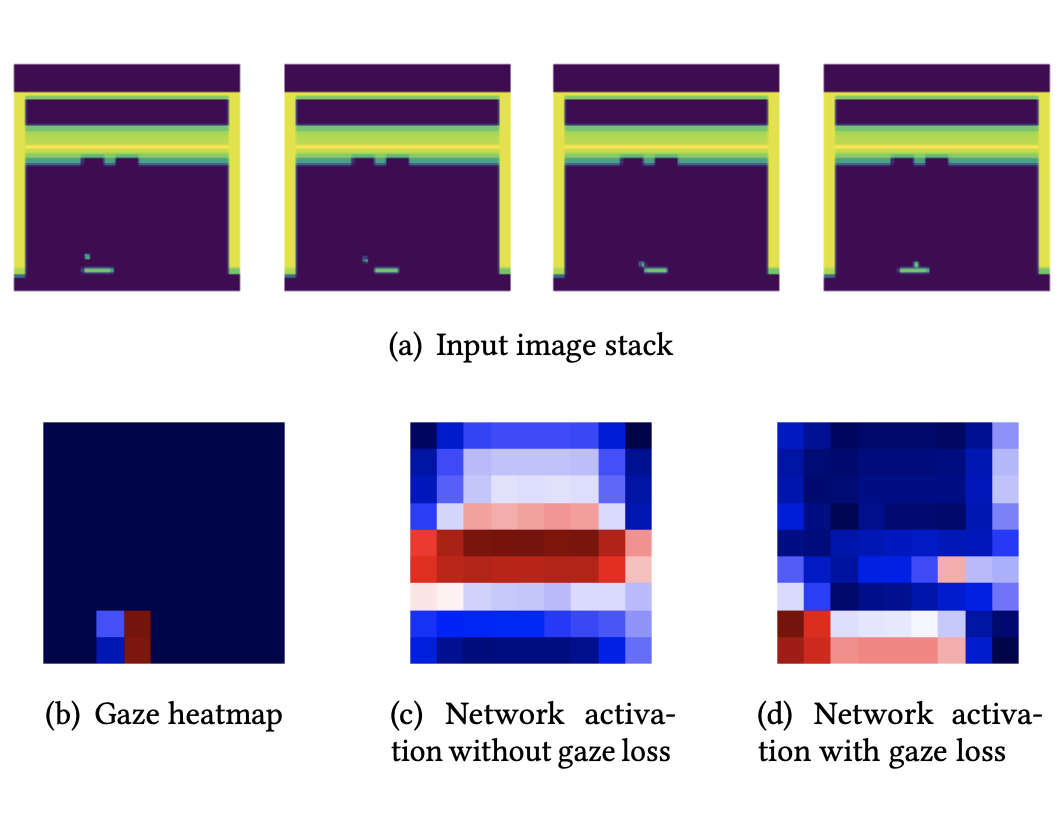
Human gaze is known to be an intention-revealing signal in human demonstrations of tasks. In this work, we use gaze cues from human demonstrators to enhance the performance of agents trained via three popular imitation learning methods -- behavioral cloning (BC), behavioral cloning from observation (BCO), and Trajectory-ranked Reward EXtrapolation (T-REX). Based on similarities between the attention of reinforcement learning agents and human gaze, we propose a novel approach for utilizing gaze data in a computationally efficient manner, as part of an auxiliary loss function, which guides a network to have higher activations in image regions where the human's gaze fixated. This work is a step towards augmenting any existing convolutional imitation learning agent's training with auxiliary gaze data. Our auxiliary coverage-based gaze loss (CGL) guides learning toward a better reward function or policy, without adding any additional learnable parameters and without requiring gaze data at test time. We find that our proposed approach improves the performance by 95% for BC, 343% for BCO, and 390% for T-REX, averaged over 20 different Atari games. We also find that compared to a prior state-of-the-art imitation learning method assisted by human gaze (AGIL), our method achieves better performance, and is more efficient in terms of learning with fewer demonstrations. We further interpret trained CGL agents with a saliency map visualization method to explain their performance. At last, we show that CGL can help alleviate a well-known causal confusion problem in imitation learning.
@inproceedings{saran2021efficiently,
title={Efficiently Guiding Imitation Learning Agents with Human Gaze},
author={Saran, Akanksha and Zhang, Ruohan and Short, Elaine Schaertl
Human demonstrators' overt visual attention can be used as a supervisory signal to guide imitation learning agents during training, such that they at least attend to visual features considered important by the demonstrator. |
 |
pdf |
abstract |
bibtex
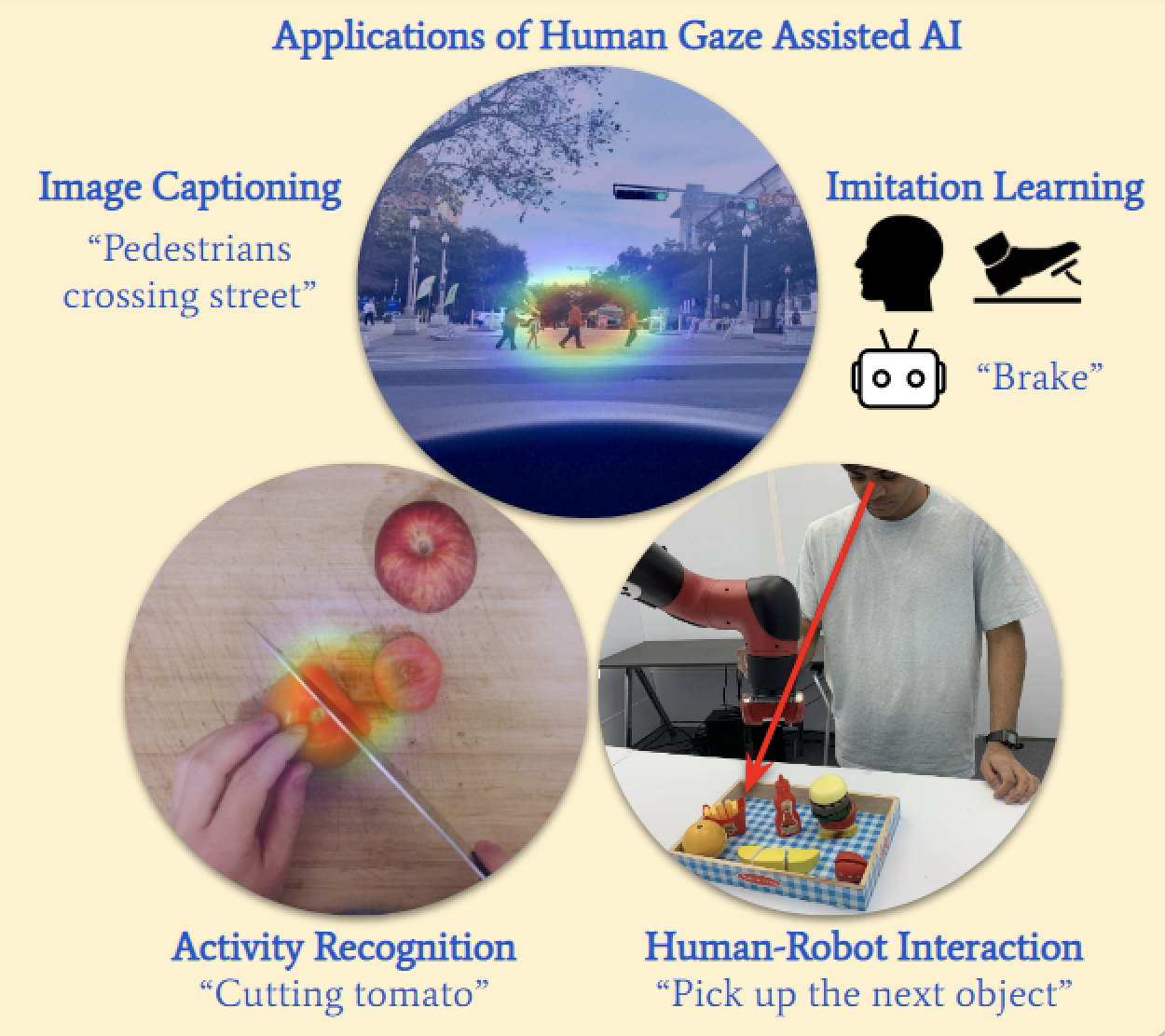
Human gaze reveals a wealth of information about internal cognitive state. Thus, gaze-related research has significantly increased in computer vision, natural language processing, decision learning, and robotics in recent years. We provide a high-level overview of the research efforts in these fields, including collecting human gaze data sets, modeling gaze behaviors, and utilizing gaze information in various applications, with the goal of enhancing communication between these research areas. We discuss future challenges and potential applications that work towards a common goal of humancentered artificial intelligence.
@inproceedings{zhang2020human,
title={Human gaze assisted artificial intelligence: A review},
author={Zhang, Ruohan and Saran, Akanksha and Liu, Bo and Zhu,
A survey paper summarizing gaze-related research in computer vision, natural language processing, decision learning, and robotics in recent years. |
 |
pdf |
abstract |
bibtex |
code |
slides |
poster |
talk video |
demo video
Human gaze is known to be a strong indicator of underlying human intentions and goals during manipulation tasks. This work studies gaze patterns of human teachers demonstrating tasks to robots and proposes ways in which such patterns can be used to enhance robot learning. Using both kinesthetic teaching and video demonstrations, we identify novel intention-revealing gaze behaviors during teaching. These prove to be informative in a variety of problems ranging from reference frame inference to segmentation of multi-step tasks. Based on our findings, we propose two proof-of-concept algorithms which show that gaze data can enhance subtask classification for a multi-step task up to 6% and reward inference and policy learning for a single-step task up to 67%. Our findings provide a foundation for a model of natural human gaze in robot learning from demonstration settings and present open problems for utilizing human gaze to enhance robot learning.
@inproceedings{saran2020understanding,
title={Understanding teacher gaze patterns for robot learning},
author={Saran, Akanksha and Short, Elaine Schaertl and
Incorporating eye gaze information of human teachers demonstrating goal-oriented manipulation tasks to robots improves perfomance of subtask classification and bayesian inverse reinforcement learning. |
 |
pdf |
abstract |
bibtex |
code |
talk video |
demo video
Gaze provides subtle informative cues to aid fluent interactions among people. Incorporating human gaze predictions can signify how engaged a person is while interacting with a robot and allow the robot to predict a human's intentions or goals. We propose a novel approach to predict human gaze fixations relevant for human-robot interaction tasks—- both referential and mutual gaze—in real time on a robot. We use a deep learning approach which tracks a human's gaze from a robot's perspective in real time. The approach builds on prior work which uses a deep network to predict the referential gaze of a person from a single 2D image. Our work uses an interpretable part of the network, a gaze heat map, and incorporates contextual task knowledge such as location of relevant objects, to predict referential gaze. We find that the gaze heat map statistics also capture differences between mutual and referential gaze conditions, which we use to predict whether a person is facing the robot's camera or not. We highlight the challenges of following a person's gaze on a robot in real time and show improved performance for referential gaze and mutual gaze prediction.
@inproceedings{saran2018human,
title={Human gaze following for human-robot interaction},
author={Saran, Akanksha and Majumdar, Srinjoy and
An approach to predict human gaze fixations relevant for human-robot interaction tasks in real time from a robot's 2D camera view. |
 |
pdf |
abstract |
bibtex |
slides |
spotlight
The visual difference between outcomes in many robotics tasks is often subtle, such as the tip of a screw being near a hole versus in the hole. Furthermore, these small differences are often only observable from certain viewpoints or may even require information from multiple viewpoints to fully verify. We introduce and compare three approaches to selecting viewpoints for verifying successful execution of tasks: (1) a random forest-based method that discovers highly informative fine-grained visual features, (2) SVM models trained on features extracted from pre-trained convolutional neural networks, and (3) an active, hybrid approach that uses the above methods for two-stage multi-viewpoint classification. These approaches are experimentally validated on an IKEA furniture assembly task and a quadrotor surveillance domain.
@inproceedings{saran2017viewpoint,
title={Viewpoint selection for visual failure detection},
author={Saran, Akanksha and Lakic, Branka and Majumdar, Srinjoy
An approach to select a viewpoint (from a set of fixed viewpoints) to visually verify fine-grained task outcomes post robot task executions. |
 |
pdf |
abstract |
bibtex
We propose a novel method for performing fine-grained recognition of human hand grasp types using a single monocular image to allow computational systems to better understand human hand use. In particular, we focus on recognizing challenging grasp categories which differ only by subtle variations in finger configurations. While much of the prior work on understanding human hand grasps has been based on manual detection of grasps in video, this is the first work to automate the analysis process for fine-grained grasp classification. Instead of attempting to utilize a parametric model of the hand, we propose a hand parsing framework which leverages a data-driven learning to generate a pixelwise segmentation of a hand into finger and palm regions. The proposed approach makes use of appearance-based cues such as finger texture and hand shape to accurately determine hand parts. We then build on the hand parsing result to compute high-level grasp features to learn a supervised fine-grained grasp classifier. To validate our approach, we introduce a grasp dataset recorded with a wearable camera, where the hand and its parts have been manually segmented with pixel-wise accuracy. Our results show that our proposed automatic hand parsing technique can improve grasp classification accuracy by over 30 percentage points over a state-of-the-art grasp recognition technique.
@inproceedings{saran2015hand,
title={Hand parsing for fine-grained recognition of human grasps
A data-driven approach for fine-grained grasp classification. |
{kind=link}
{kind=link}
|
|